A gépi tanulás már az ókori görög szövegeken is segít
A mesterséges intelligenciával folytatott kísérletek a történelemtudományban is elkezdődtek, elég jó eredményekkel. A Nature friss tanulmánya szerint az ókori görög táblafeliratok pontosabban visszaállíthatók gépi tanulással, mint történészekkel.
Kézenfekvő ötlettel állt elő a Nature újonnan megjelent tanulmánya a történelmi terület és a gépi tanulás lehetőségeinek összekapcsolásával. Ha van rengeteg történészek által már feldolgozott szöveg, jelen esetben ókori görög kőbe, kerámiába vagy fémbe vésett felirat, akkor a gépi tanulás a meglévő anyagok alapján javaslatot tehet a fennmaradó töredékes szövegek rekonstruálására, készülési helyének és idejének meghatározására. A történészek legnagyobb problémája, hogy az idő során a feliratok sérültek, illetve a készülésük pontos idejét és helyét sem lehet tudni, mivel a felirathordozókat az évszázadok során bárhová szállíthatták eredeti helyéről. Mindez rendkívül nehézkessé teszi a szövegek restaurálását és megértését vagyis az epigráfia tudományát.
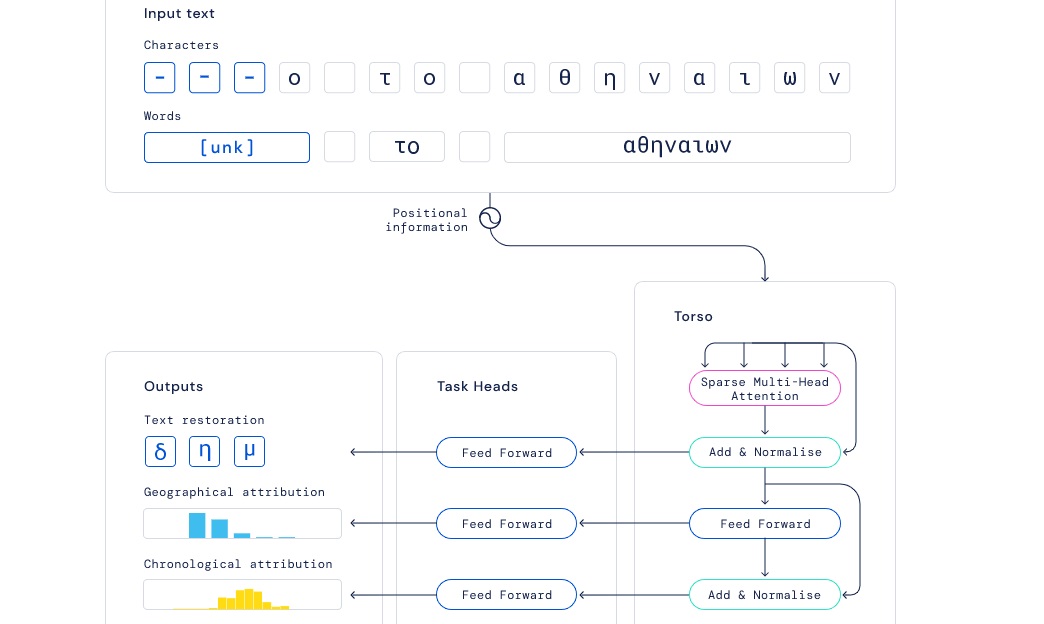
A tanulmány szerzői az Alphabet-féle DeepMind Ithaca mély neurális hálózatot vették igénybe a vizsgálathoz, melynek során a Packard Humanities Institute 185,5 ezer feliratából álló adatkészletét dolgozták fel. A vizsgálatban a kutatók a betűket és a szavakat egyaránt figyelembe vették a szövegkörnyezet értelmezhetősége érdekében, miközben a sérült betűket speciális karakterrel helyettesítették.
A kutatók szerint a gépek és az emberek együttműködése vezet a leghatékonyabb eredményre, ezért a folyamatot is így alakították. A beolvasott szövegek közül történészek segítségével meghatározták a helyreállítási feladatok nehézségét, valamint a mintaként használható szöveges párhuzamokat. Majd a történészek számára bemutatták az Ithaka 20-20 legvalószínűbbnek jelölt restaurációs hipotézisét, és a (szintén DeepMind-féle) Pythia neurális hálózat elvégezte a visszaállítási feladatot. Végül a szakértők felcímkézték a szövegben az ismert görög személyneveket, ami a lokáció és az időszak meghatározása miatt lényeges.
Az eredmény elég meggyőző a szövegek visszaállításában, illetve helyének és idejének meghatározásában is. A Nature tanulmánya szerint az Ithaca önmagában is 61,8 százalékos pontossággal restaurálja a sérült szövegrészleteket, de emellett a történészek munkáját is 25,3 százalékról 71,7 százalékos pontosságra növelte. A szöveg készítési helyszínének meghatározása 70,8 százalékos a névtannal foglalkozók 21,2 százalékos értékeihez képest. A szöveg keletkezési idejét az eszköz szintén jobban meg tudja becsülni, nagyjából 29 éven belüli pontossággal, ami a névtanosoknak 144 éven belüli értékekkel sikerült a tesztadatokon.
A tanulmány szerzői a görög történelem segítése mellett egy általánosabb kutatási célt is választottak, annak bizonyítását, hogy a mesterséges intelligencia hasznos eszköz lehet a történészek kezében. Az Ithaka segítségével a kutatók most is próbálkozhatnak akkád, démotikus, héber és maja adatkészletek tanulmányozásával, de a jövőben a DeepMind más ókori nyelveket is szeretne elemezhetővé tenni. Az Ithaka nyílt forrású kódja GitHubon megtalálható, az oldalon pedig az ókori görög feliratok kutatói kísérletezhetnek az eszközzel, mások pedig az előre megadott példaszövegekkel.